推薦系統作為人工智能領域的重要應用,已在電商、內容平臺、社交網絡等行業中發揮關鍵作用。企業級推薦系統的構建不僅涉及算法優化,更離不開工程實現和數據基礎設施的支持。本文聚焦推薦系統的工程實現環節,并探討人工智能公共數據平臺在其中的作用。
一、推薦系統的工程架構
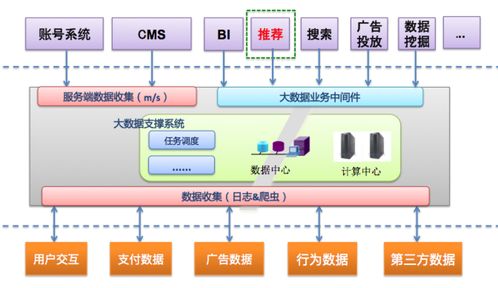
企業級推薦系統通常采用模塊化設計,包括數據采集、特征工程、模型訓練、在線服務和反饋閉環等核心模塊。數據采集模塊負責從用戶行為日志、商品信息、上下文數據等源頭收集原始數據;特征工程模塊對原始數據進行清洗、轉換和特征提取,生成模型可用的輸入特征;模型訓練模塊基于離線或在線學習算法,生成推薦模型;在線服務模塊通過低延遲的API接口,實時響應用戶的推薦請求;反饋閉環模塊則收集用戶對推薦結果的反饋,用于模型的持續優化。
工程實現中,系統需要兼顧高可用性、可擴展性和實時性。例如,采用微服務架構將各模塊解耦,通過容器化部署提升資源利用率;使用分布式計算框架(如Spark、Flink)處理海量數據;引入緩存和負載均衡技術保證在線服務的高并發訪問。
二、人工智能公共數據平臺的角色
人工智能公共數據平臺為推薦系統提供了統一的數據管理和計算基礎設施。該平臺整合多源數據(如用戶畫像、商品屬性、行為日志),并提供數據存儲、數據治理和數據處理能力。通過平臺的數據湖或數據倉庫,推薦系統可以高效訪問結構化和非結構化數據,減少數據孤島問題。
平臺還支持特征庫的構建,將常用特征(如用戶興趣向量、物品相似度)標準化和復用,加速模型迭代。平臺提供的分布式訓練環境和模型管理工具,簡化了從實驗到生產的全流程,例如通過MLOps實踐實現模型的自動化部署和監控。
三、案例與實踐
以某電商平臺為例,其推薦系統工程實現中,利用人工智能公共數據平臺整合了用戶瀏覽、購買歷史和實時點擊流數據。平臺通過流處理技術實時更新用戶特征,并結合離線訓練的深度學習模型,生成個性化推薦。工程團隊采用A/B測試框架驗證效果,并通過平臺的數據分析工具監控指標(如點擊率、轉化率),持續優化系統。
四、挑戰與未來展望
推薦系統工程化面臨數據隱私、系統復雜性等挑戰。未來,隨著邊緣計算和聯邦學習的發展,推薦系統將更注重數據安全與效率平衡。人工智能公共數據平臺的演進,如集成自動化機器學習(AutoML)和可解釋AI工具,將進一步提升推薦系統的智能化水平。
推薦系統的成功離不開堅實的工程實現和高效的數據平臺。企業需在技術選型、團隊協作和流程優化上投入資源,以構建可持續演進的推薦生態系統。